
異動資料(Transaction data)顧名思義是指來自交易等異動的資料。例如:店家會登記商店裡每一筆銷售的資料;我們會登記銀行帳戶每月的餘額。為了用這些異動資料來預測靜態的結果,我們通常會加總這些變數成靜態的觀點(view)。一般的做法是先決定一個時間視窗(time window),例如最近六個月,然後找出這些交易的總合計、最大交易量、最小交易量等。
以下圖資料為例,使用pandas,統計每個使用者使用次數和使用時間總和。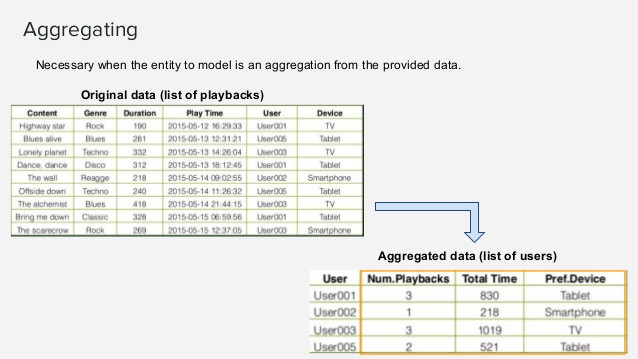
圖片來源:www.slideshare.net/gabrielspmoreira/feature-engineering-getting-most-out-of-data-for-predictive-models-tdc-2017
data = pd.read_csv('../input/sample10.csv')
data
/|Content| Genre| Duration| Play Time| User| Device
------------- | -------------
0| Highway star| Rock| 190| 2015/6/12 04:29 |User001| TV
1| Blue alive| Blues| 281| 2015/6/13 12:31 |User005 |Tablet
2| Lonely Planet| Techno| 332| 2015/6/13 18:12| User003| TV
3| Dance, dance| Disco| 312| 2015/6/13 18:12| User001 |Tablet
4| The wall| Reagge| 218 |2015/6/14 21:29 |User002 |Smartphone
5| Offside down| Techno| 240| 2015/6/14 16:29| User005| Tablet
6| The alchemist| Blues| 418| 2015/6/14 16:29| User003| TV
7| Bring me down| Classic| 328| 2015/6/15 16:29| User001| Tablet
8| The scarocrow| Rock| 269| 2015/6/15 16:29| User003| Smartphone
檢視使用者數目:
print('Number of users: {}'.format(data['User'].nunique()))
Number of users: 4
顯示每個使用者使用次數:
data.groupby('User')['Play Time'].count()
User|
------------- | -------------
User001 | 3
User002| 1
User003 | 3
User005 | 2
Name: Play Time, dtype: int64
使用pandas彙總使用者資料:
# 要使用的統計功能
operations = ['count','max', 'min', 'mean','sum']
# 欄位名稱
feature_names = ['NumPlaybacks', 'max_Time', 'min_Time', 'mean_Time','Total Time']
df = pd.DataFrame()
df[feature_names] = data.groupby('User')['Duration'].agg(operations)
df
/|NumPlaybacks| max_Time| min_Time| mean_Time| Total Time
------------- | -------------
User001 |3| 328| 190| 276.666667| 830
User002| 1| 218| 218| 218.000000| 218
User003| 3| 418| 269 |339.666667| 1019
User005| 2| 281| 240| 260.500000| 521
Pivoting()是選取一個變數,並把它下面的不同值設定為新的欄位,再對這些新欄位進行彙總計算。
圖片來源:www.slideshare.net/gabrielspmoreira/feature-engineering-getting-most-out-of-data-for-predictive-models-tdc-2017
讓我們選取"Device"這個欄位。
print('Number of devices: {}'.format(data['Device'].nunique()))
Number of devices: 3
統計使用者使用這些新欄位(各種Device)使用的時間:
data.pivot_table(index='User', columns='Device',
values='Duration', aggfunc=np.sum, fill_value = 0)
Device | Smartphone | TV | Tablet
------------- | -------------
User | | |
User001 |0 |190 | 640
User002 |218 | 0 |0
User003 | 269 | 750 | 0
User005 | 0 | 0 | 521
統計使用者使用這些新欄位(各種Device)使用的次數:
df_p = data.pivot_table(index='User', columns='Device',
values='Play Time', aggfunc='count', fill_value = 0)
Device|Smartphone |TV| Tablet
------------- | -------------
User| | |
User001| 0| 1 |2
User002| 1| 0| 0
User003| 1| 2| 0
User005| 0| 0| 2
接下來我們可以將這些資料merge,進行機器學習。

 iThome鐵人賽
iThome鐵人賽